
Breve introducción al ANOVA de una vía o de un factor entre-grupos.
Veremos cuáles son los supuestos de la prueba y cuándo debes usarla. Te mostraremos cómo realizar el ANOVA, cómo interpretar los resultados y cómo informar de ellos en formato científico.
Contenido
- 1 ¿Para qué sirve esta prueba?
- 2 Hipótesis nula y alternativa
- 3 Regla de decisión
- 4 ¿Cuándo necesitarás usar esta prueba?
- 5 ¿Por qué no comparar grupos con múltiples pruebas t?
- 6 ¿Qué supuestos tiene la prueba?
- 7 ¿Qué sucede si mis datos no cumplen estos supuestos?
- 8 ¿Qué son las pruebas post hoc?
- 9 ¿Qué prueba post hoc debo usar?
- 10 ¿Cómo puedo informar los resultados del ANOVA?
- 11 ¿Qué hacer ahora?
¿Para qué sirve esta prueba?
El análisis de varianza (ANOVA) de una vía se utiliza para determinar si existen diferencias estadísticamente significativas entre las medias de tres o más grupos.
En este caso utilizaremos grupos independientes (no relacionados) por lo que lo llamaremos ANOVA de un factor entre-grupos.
Luego de realizar el ANOVA, si los grupos presentan un comportamiento distinto, podremos determinar entre qué grupos específicos existen diferencias estadísticamente significativas mediante pruebas de comparación múltiple post hoc.
Resumiendo, vamos a responder a las siguientes preguntas:
¿Los grupos (3 o más) son diferentes -para una cierta variable respuesta-?
Si la respuesta es afirmativa, ¿qué grupos son diferentes?
Algunos ejemplos
- Un grupo de pacientes psiquiátricos se encuentra bajo tres diferentes terapias: asesoramiento, medicamentos y deporte, y queremos ver si una terapia es mejor que las otras.
- Un fabricante tiene varios procesos diferentes para fabricar bombillas y quiere saber si un proceso es mejor que el otro.
- Los estudiantes de diferentes colegios toman el mismo examen y deseamos ver si una universidad supera a la otra en la puntuación.
¿Por qué se llama ANOVA?
El nombre Analysis of Variance (ANOVA), análisis de varianza, se basa en el enfoque en el que el procedimiento utiliza varianzas para determinar si las medias son diferentes. El procedimiento funciona comparando la varianza entre las medias de grupo (entre-grupos) versus la varianza dentro de los grupos (intra-sujetos) como una forma de determinar si los grupos son más distintos entre sí que dentro de sí.
¿Por qué hablamos de “una vía”? Y ¿Qué son los grupos o niveles?
Una vía significa que tenemos una única variable explicativa o predictor, también llamada variable independiente. Esta variable debe tener tres o más niveles o categorías.
Por ejemplo, si queremos analizar el pH de distintas muestras de jabón de bebé, la marca del jabón es nuestra variable independiente cuyos niveles podrían ser Baño Dulces Sueños de Johnson’s Baby, Champú-Gel de Weleda, Gel Champú de Suavinex y Babygel de Mustela Beb.
¿Quién creó esta prueba?
El ANOVA, desarrollado por Ronald Fisher en 1918, extiende la prueba t y la prueba z que compara tan solo 2 grupos. Este británico (1890 – 1962) fue un estadístico y biólogo que usó la matemática para combinar las leyes de Mendel con la selección natural, de manera que ayudó así a crear una nueva síntesis del Darwinismo conocida como la síntesis evolutiva moderna.
Hipótesis nula y alternativa
- Hipótesis nula, H0: las medias de los grupos son iguales. μ1 = μ2 = … = μk
- Hipótesis alternativa, H1: alguna de las medias es distinta. μi ≠ μj para algún i y j
Donde μ es la media del grupo y k el número de grupos.
Regla de decisión
Elegimos el nivel alfa de significación que vamos a utilizar, usualmente alfa=5% o 0,05.
- Cuando el p-valor del estadístico de la prueba ANOVA es inferior al nivel alfa de significación que hemos elegido, entonces rechazamos la hipótesis nula y nos quedamos con la alternativa.Es decir, hay al menos dos medias grupales que son diferentes entre sí.
- En caso contrario, no podemos rechazar la hipótesis nulay concluimos que no existen diferencias significativas entre los grupos evaluados.
Es importante recordar que la prueba ANOVA no nos dice nada acerca de qué grupos específicos son diferentes. Para ello debemos realizar pruebas de comparación múltiple post hoc, que veremos más adelante.
¿Cuándo necesitarás usar esta prueba?
- Situación 1:Cuando tenemos un grupo de individuos divididos aleatoriamente en grupos más pequeños bajo distinto tratamiento. Por ejemplo, usted podría estar estudiando los efectos del té en la pérdida de peso y formar tres grupos: el té verde, té negro, y sin té.
- Situación 2:Similar a la situación 1, pero en este caso los individuos se dividen en grupos basados en un atributo que poseen. Por ejemplo, usted podría estar estudiando la fuerza de las piernas de las personas de acuerdo al peso. Podría dividir a los participantes en categorías de peso (obesidad, sobrepeso y normal) y medir la fuerza de sus piernas en una máquina de peso.
¿Por qué no comparar grupos con múltiples pruebas t?
Cada vez que realizas una prueba t, existe la posibilidad de que obtengas un error de tipo I (o falso positivo, es el error que se comete cuando no aceptamos la hipótesis nula siendo esta realmente verdadera). Este error suele ser del 5% (nivel alfa de significación del que hablamos antes). Al ejecutar dos pruebas t sobre los mismos datos, habrá aumentado la probabilidad de “cometer un error” al 10%. La fórmula para determinar la nueva tasa de error para múltiples pruebas t no es tan simple como multiplicar el 5% por el número de pruebas. Sin embargo, si usted está haciendo solamente algunas comparaciones múltiples, los resultados son muy similares. Como tal, tres pruebas t serían el 15% (en realidad, el 14,3%) y así sucesivamente. Estos son errores inaceptables. Un ANOVA controla estos errores para que el tipo de error I permanezca en 5% y así podamos estar más seguros de nuestros resultados.
¿Qué supuestos tiene la prueba?
- La variable dependiente o respuesta debe ser continua.Por ejemplo, el tiempo de revisión (medido en horas), inteligencia (medida mediante la puntuación de CI), desempeño del examen (medido de 0 a 100), peso (medido en kg), etc.
- La variable independiente o explicativa debe estar formada por tres o más grupos categóricos e independientes.Por ejemplo, la etnicidad (caucásico, afroamericano e hispano), el nivel de actividad física (sedentario, bajo, moderado y alto), la profesión (doctor, enfermera, dentista, terapeuta), etc.
- La variable dependiente se distribuye normalmente en cada grupoque se compara en el ANOVA de una vía (técnicamente, son los residuos los que necesitan ser distribuidos normalmente, pero los resultados serán los mismos). Puedes probar la normalidad usando la prueba de normalidad de Shapiro-Wilk.
- Hay homogeneidad de varianzas.Esto significa que las varianzas de la respuesta en cada grupo son iguales. Puedes probar esta suposición usando la prueba de Levene para la homogeneidad de las varianzas.
- Las observaciones son independientes.Esto es principalmente un tema del diseño del estudio y, como tal, necesitará determinar si cree que es posible que sus observaciones no sean independientes en función del diseño del estudio (por ejemplo, si los valores han sido tomados diariamente las muestras más cercanas en el tiempo serán más similares entre sí respecto al resto de muestras -correlación temporal-).
- No debemos tener valores atípicos (outliers) influyentes.Los valores atípicos son simplemente valores dentro de sus datos que no siguen el patrón habitual (por ejemplo, en un estudio de 100 puntajes de IQ de los estudiantes, donde la puntuación media fue de 108 con sólo una pequeña variación entre los estudiantes; pero un sujeto obtuvo un valor de 156, que es muy inusual incluso en la bibliografía). El problema con los valores atípicos es que pueden afectar el resultado del ANOVA, reduciendo la validez de sus resultados. Puedes leer [aquí] cómo detectar valores atípicos usando R y ver algunas opciones para tratarlos.
¿Qué sucede si mis datos no cumplen estos supuestos?
En primer lugar, no te asustes.
Esto no es raro cuando se trabaja con datos del mundo real en lugar de ejemplos de libros de texto, que a menudo sólo le muestran cómo llevar a cabo un ANOVA de una vía cuando todo va bien. No te preocupes, incluso cuando sus datos fallan ciertas suposiciones, hay a menudo una solución para superar esto. El incumplimiento de los dos primeros de estos supuestos puede no ser tan grave y existen alternativas como las pruebas no paramétricas (que no requieren supuestos acerca de la distribución de los datos).
- El ANOVA de una vía se considera una prueba robusta frente a la falta de normalidad.Esto significa que tolera las violaciones a su supuesto de normalidad bastante bien siempre que no sea demasiada. Puede tolerar datos que no son normales (distribuciones sesgadas o empinadas) con sólo un pequeño efecto sobre la tasa de error Tipo I. Sin embargo, las distribuciones aplanadas pueden tener un efecto profundo cuando los tamaños de grupo son pequeños. Esto nos deja con dos alternativas: (1) transformar los datos para que la forma de la distribución sea normal o (2) elegir una prueba no paramétrica que no supone normalidad.
- En el caso de que no exista homogeneidad de variantes podemos aplicar el ANOVA de Welch y una prueba de Games-Howell en lugar de una prueba post hoc de Tukey. Otra alternativa es aplicar una prueba no paramétrica.
- La falta de independencia de los casos es la más grave.Deberíamos pensar en otro tipo de prueba para hacer frente a este problema, por ejemplo un diseño de medidas repetidas.
Recuerda que si no consideras correctamente estos supuestos, los resultados obtenidos al ejecutar una ANOVA podrían no ser válidos.
¿Qué son las pruebas post hoc?
Recuerda que la prueba ANOVA nos indica si existen diferencias entre los grupos, pero no nos dice qué grupos específicos son diferentes, para ello debemos realizar pruebas post hoc o a posteriori. Su nombre indica que se ejecutan para confirmar donde ocurrieron las diferencias entre los grupos, por lo cual debes recordar que sólo se deben realizar cuando se detecta una diferencia estadísticamente significativa en las medias de los grupos (es decir, cuando un resultado del ANOVA de una vía es estadísticamente significativo). Las pruebas post hoc intentan controlar la tasa de errores experimentales (usualmente alfa = 0,05) de la misma manera que se usa el ANOVA de una vía en lugar de múltiples pruebas t.
¿Qué prueba post hoc debo usar?
Hay un gran número de diferentes pruebas post hoc que puedes utilizar luego del ANOVA de una vía. Si los datos cumplen con la hipótesis de homogeneidad de las varianzas, utilice la prueba post hoc de Tukey (HSD). Si sus datos no cumplen con la suposición de homogeneidad de varianzas, utilice la prueba post hoc de Games Howell.
¿Cómo puedo informar los resultados del ANOVA?
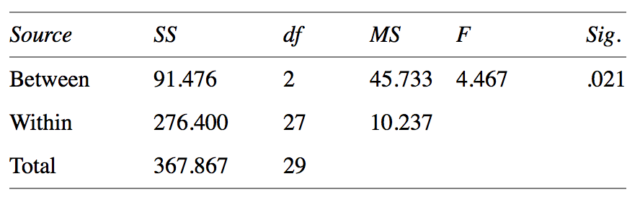
Los resultados de la prueba ANOVA de una vía se suelen disponer de la siguiente manera:
¿Qué debo informar?
Todo lo que necesitas escribir sobre el resultado del ANOVA es si encontraste o no diferencias significativas e informar del valor del estadístico F, sus grados de libertad (df), su valor, y el p-valor calculado (sig.).
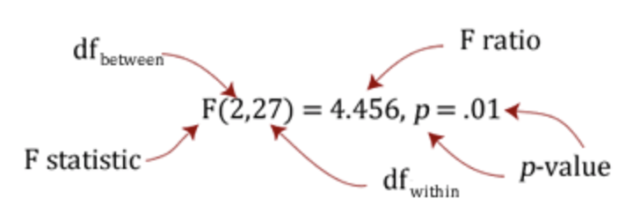
Mi p-valor es mayor que 0.05, ¿qué hago ahora?
Informe el resultado del ANOVA de una vía aún si el resultado no es estadísticamente significativo. Por ejemplo, “No detectamos diferencias estadísticamente significativas entre las medias de los grupos como se determinó por ANOVA de una vía (F (2,27) = 1,397, p = 0,15)”). Eso sí, no será necesario realizar la prueba post hoc.
Mi p-valor es menor que 0.05, ¿qué hago ahora?
En el ejemplo que ponemos arriba deberíamos decir que: “Detectamos una diferencia estadísticamente significativa entre los grupos mediante el ANOVA de una vía (F (2,27) = 4,467, p = 0,021)”. Sin embargo, es probable que también queramos informar del resultado de la prueba de comparaciones múltiple post hoc y del valor medio ± desviaciones estándar para los grupos.
¿Cómo debo presentar gráficamente mis resultados?
No es necesario que presentes tus resultados mediante un gráfico pero puede facilitar la interpretación de los resultados. En el caso de que lo desee, recomiendo utilizar un gráfico de medias con desviación estándar. Algunos investigadores suelen usar barras con desviación estándar pero recuerda que la media es un valor único, no acumulable, por lo cual la barra no tiene mucho sentido (aunque lo verá en un sin fin de artículos científicos, desgraciadamente).
Es necesario presentar los intervalos de error para la media de cada grupo. Generalmente se utiliza la desviación estándar de cada grupo, pero también se pueden usar los errores estándar o los intervalos de confianza.
¿Qué hacer ahora?
En la siguiente entrada te mostraré un ejemplo muy simpático para realizar esta prueba con el Software R. ¡Todo los pasos que necesitas hacer para obtener los resultados que buscas!
¡No te olvides de dejarnos tu comentario!







Buen post, muchas gracias por la informacion.. aun tengo algunas dudas con mi estadistico espero puedan ayudarme. En mi trabajo de invetigacion estoy evaluando si el tratamiento que le doy a ratones baja los niveles de glucosa posprandial. tengo una n=3 por grupo, 4 grupos en total, un control negativo, un positivo (medicamento), uno con tratamiento de prueba en dosis de 50 y otro en tratamiento de prueba con dosis de 100, tomamos una muestra de glucosa inicial a tiempo 0 damos tratamiento y posteriormente tomamos muestras de glucosa cada media hora para evaluar los niveles de glucosa, hacemos 4 tomas. queremos evaluar nuestros tratamientos con respecto al control, aplique una prueba de normalidad de SHAPIRO-WILK y me dice que mis datos son normales, hice despues una Anova de 2 vias y comparacion multiple de medias con Tukey, me arrojo diferencias significativas, mi grafica es niveles de glucosa con respecto al tiempo ( 30, 60, 90 y 120 min) sin embargo en la revision de mis resultados me hacen la observacion que este tipo de analisis no se aplica una Anova ya que es el mismo sujeto con respeto al tiempo y eso me confunde, no se que prueba aplicar, me podrian ayudar, gracias.
Estimado Timothy. Puedes escribirnos a comunicacion@maximaformacion.es y derivamos tu consulta a nuestro equipo de consultores. También te recomendamos participar en la XII edición del Máster de Estadistica con R Software de Máxima Formación, que dará inicio en el mes de marzo de 2021. Con este programa formativo 100% adquirirás habilidades avanzadas para gestionar tus datos con rigor científico https://www.maximaformacion.es/curso/master-de-estadistica-aplicada-con-r-software/ Somos formadores Data Science del Consejo Superior de Investigaciones Científicas (CSIC), y estamos especializados en la capacitación avanzada de investigadores en Ciencia de Datos con R Software. Estaríamos encantados de contar contigo.
Un abrazo